


Centos6.6下对Hadoop2.2.0版本进行安装和部署,此处LZ用的Centos32位的系统,由于64位安装时会出现某种莫名其妙的问题,故使用32位。下面提供32位Centos6.6下载地址
实验环境:三台Centos6.6系统(由于实验环境,只分发了两个节点)
32位Centos镜像地址:http://pan.baidu.com/s/1pKB7TFX 密码:61af
32位Linux下JDK: http://pan.baidu.com/s/1nv40AM1 密码:wijs
Hadoop2.2.0安装包:https://archive.apache.org/dist/hadoop/common/
根据上面提供的32位镜像地址,建立虚拟机,实验环境装了3台虚拟机,大家可以根据自己的需求建立虚拟机。
安装Hadoop2.2.0详细步骤如下:
1、安装JDK,根据上述提供的地址下载后,在系统中进行解压文件,解压步骤LZ不再详述,此处LZ解压在usr目录下,此处记录好自己的安装目录,后面配置hadoop环境变量会用到。(ps:此处安装的JDK位数,一定要与Linux系统的位数保持一致,如果不一致,安装过程中会出现问题)

2、编辑hosts文件,此处设置参与集群需要用到的主机名,IP地址对应主机名。统一都用主机名(切记有一些用主机名,一些用IP地址。免密码连接需用到)

3、关闭防火墙。必须对每一台节点的防火墙进行关闭,如果不关闭会出现无法建立连接的问题。
关闭防火墙的命令 service iptables stop 关闭防火墙
service iptables status 查看状态
service iptables start 开启防火墙
chkconfig iptables off 设置开机关闭防火墙
4、部署免密码SSH 这一步骤可以参考我的的另一篇文章(免密码登录服务器):
5、下载Hadoop2.2.0并解压。上述已经提供下载地址,可根据地址下载后,上传至服务器。或者如果需要在服务器上直接下载,可以利用wget命令+下载地址进行下载,如下:

下载后在解压文件:tar -xzvf hadoop-2.2.0.tar.gz
解压后在目录中创建data(存放数据块,用于datanode)、name(存放元数据,用于namenode)、tmp(临时目录)文件夹。如下图:

6、修改hadoop中的配置文件
1)、/hadoop-2.2.0/etc/hadoop/hadoop-env.sh文件, 此文件中需要修改hadoop的环境变量,设置JAVA_HOME路径。在hadoop-env.sh 文件中找到JAVA_HOME,将自己的JDK安装目录设置上即可。LZ这里的JDK上安装到/usr/目录下。如图:

2)、/hadoop-2.2.0/etc/hadoop/yarn-env.sh文件,此文件中亦需要修改yarn的环境变量,设置JAVA_HOME路径。

3)、/hadoop-2.2.0/etc/hadoop/slaves文件,此文件中需要设置与主机相关联的子节点主机名,LZ因为只设置了两个子节点,故只需设置两个主机名即可,大家可以根据自己的情况设置对应的子节点的主机名。如图:

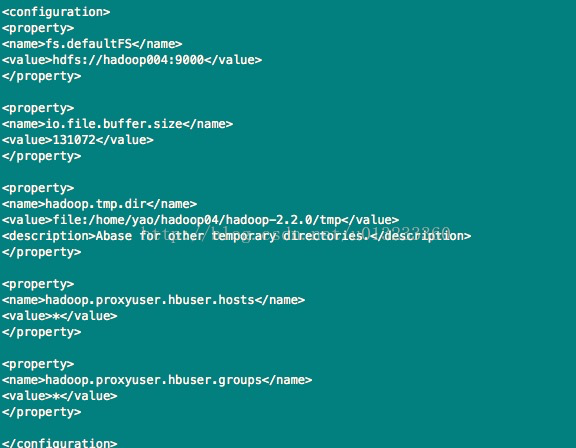
4)、/hadoop-2.2.0/etc/hadoop/core-site.xml文件,设置如下:
fs.defaultFS中的值为namenode的主机,监听9000端口
hadoop.tmp.dir中的值设置hadoop的临时目录
core-site.xml文件的配置项较多,此处不一一赘述。
可参考《Hadoop权威指南》书中第九章第四节Hadoop的配置,该小节中对配置属性均有解释。
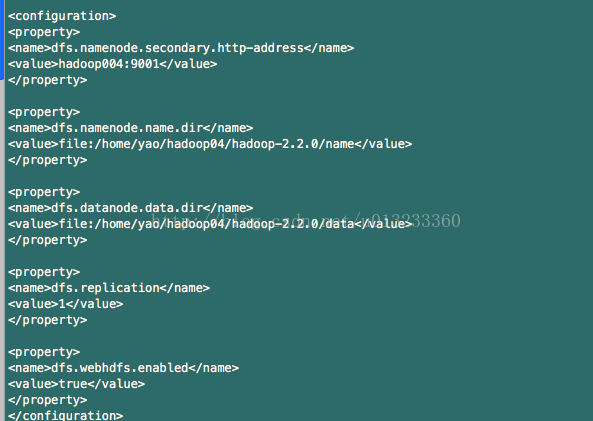
5)、/hadoop-2.2.0/etc/hadoop/hdfs-site.xml文件,配置如下:
dfs.namenode.name.dir 的值指定元数据存放的目录(name目录需要预先建立好)
dfs.datannode.name.dir 的值指定数据块存放的目录 (data目录需要预先建立好)
可参考《Hadoop权威指南》书中第九章第四节Hadoop的配置,该小节中对配置属性均有解释。
6)、/hadoop-2.2.0/etc/hadoop/mapred-site.xml文件,配置项如下:(ps:hadoop2.2.0的mapred-site.xml文件名字为是“mapred-site.xml.template ”)
mapreduce.framework.name的值设置mapreduce的框架为第二代的yarn
可参考《Hadoop权威指南》书中第九章第四节Hadoop的配置,该小节中对配置属性均有解释。

7)、/hadoop-2.2.0/etc/hadoop/yarn-site.xml文件,配置如下:
可参考《Hadoop权威指南》书中第九章第四节Hadoop的配置,该小节中对配置属性均有解释。
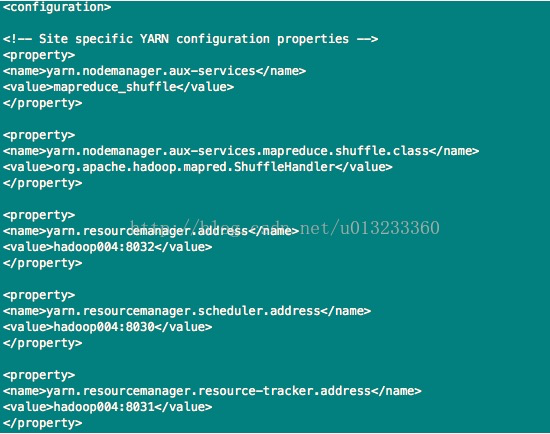
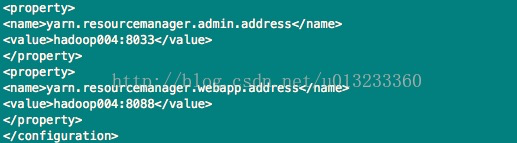
7、分发hadoop到各个节点
配置好上述的文件后,就可以将hadoop的包分发到各个节点上,这里分发了两个节点,分别作为数据块节点。
8、启动集群
最后一步,启动集群,首先需要格式化namenode。
格式化命令:./bin/hdfs namenode-format
格式化后,如果出现成功Successfully表明已格式化成功,就可以进行启动Hadoop集群了。
启动hdfs:./sbin/start-dfs.sh
启动后,可以根据/usr/jdk1.7.0_67/bin/jps查询进程(ps:根据JDK安装的目录来进行查询进程)
此时主节点上的进程有 namenode,secondarynamenode
两个子节点上的进程有datanode
如图:主节点的进程

子节点的进程

启动yarn:./sbin/start-yarn.sh
此时的主节点上运行的进程有:namenode、secondarynamenode、resourcemanager
字节点上面运行的进程有:datanode、nodemanager
如图:主节点的进程

子节点的进程

也可以通 ./sbin/start-all.sh 启动整个hadoop集群
启动后可以根据web页面了解Hadoop的运行状态
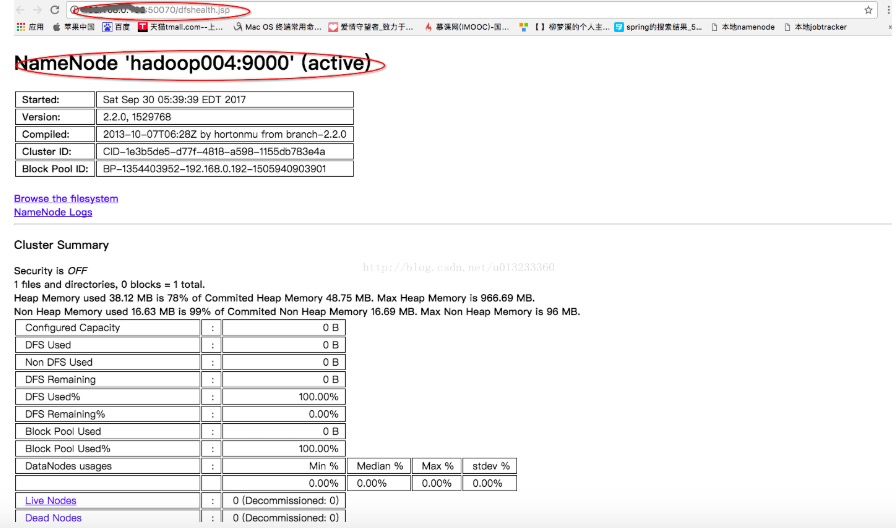
如果看到上述web页面的情况,Hadoop2.2.0版本安装及部署就全部完成




