


我们刚接触第一个算法的时候,大概都会是排序算法,今天学习积累两种排序算法,分别是冒泡排序与插入排序。
如何分析一个排序算法?
- 排序算法的执行效率
我们知道,一个算法写的好不好,第一点往往从它的执行效率来判定。对于排序算法执行效率的分析,我们一般会从这几个方面来衡量:
- 最好情况、最坏情况、平均情况时间复杂度
一个排序算法需要考虑到多种环境情况下执行的时间复杂度。 - 时间复杂度的系数、常数 、低阶
时间复杂度的测试会通过不同规模的数据来做考量。 - 比较次数和交换(或移动)次数
在做排序的时候,会涉及数据的交换、比较、移动等操作,如果需要分析排序的效率,必然要考虑这些因素。
- 排序算法的内存消耗
算法的内存消耗可以通过空间复杂度来衡量,排序算法也不例外。不过,针对排序算法的空间复杂度,我们还引入了一个新的概念,原地排序(Sorted in place)。原地排序算法,就是特指空间复杂度是 O(1) 的排序算法。 - 排序算法的稳定性
仅仅用执行效率和内存消耗来衡量排序算法的好坏是不够的。针对排序算法,我们还有一个重要的度量指标,稳定性。这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
冒泡排序
冒泡排序可以说是我接触的第一个排序算法了,相对来说比较简单,它只会操作相邻的两个数据,将相邻的两个数据进行比较,如果符合排序条件,则相互交换。一次冒泡操作会使当前数据移动到它该到的位置,重复n次,则排序完成。
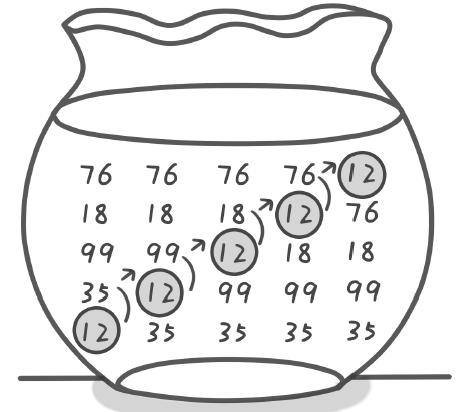
具体实现代码如下:
/**
* 冒泡排序
*
* @param sort
* @param size
*/
public static void bubble(int[] sort, int size) {
if (size <= 1) {
return;
}
for (int i = 0; i < size; i++) {
for (int j = i + 1; j < size; j++) {
if (sort[i] > sort[j]) {
int tmp = sort[j];
sort[j] = sort[i];
sort[i] = tmp;
}
}
}
}
- 冒泡算法属于原地排序算法,冒泡过程只涉及到两个数据之间的交换,只需要常量级的临时空间,空间复杂度为O(1)
- 在冒泡排序中,只有交换才可以改变两个元素的前后顺序。为了保证冒泡排序算法的稳定性,当有相邻的两个元素大小相等的时候,我们不做交换,相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。
- 冒泡排序的最好时间复杂度是O(n),最坏时间复杂度为O(n平方)。
插入排序
顾名思义,在排序阶段将符合条件的数据直接插入到待排序位置,然后将后面的数据进行搬移。
插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。
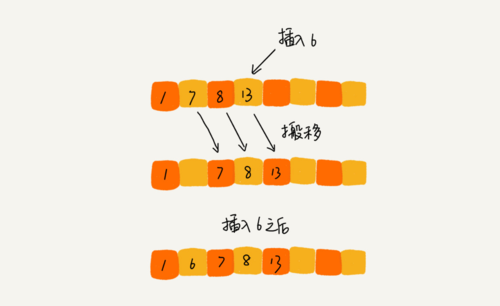
具体实现代码如下:
/**
* 插入排序
*
* @param a
* @param n
*/
public static void insertionSort(int[] a, int n) {
if (n <= 1) return;
for (int i = 1; i < n; ++i) {
//当前数据
int value = a[i];
//寻找插入位置的起始值
int j = i - 1;
// 查找插入的位置
for (; j >= 0; --j) {
//当前值大于比较的值
if (a[j] > value) {
//数据移动
a[j + 1] = a[j];
} else {
break;
}
}
//插入数据
a[j + 1] = value;
}
}
- 插入排序算法的运行并不需要额外的存储空间,所以空间复杂度是 O(1),也就是说,这是一个原地排序算法。
- 在插入排序中,对于值相同的元素,我们可以选择将后面出现的元素,插入到前面出现元素的后面,这样就可以保持原有的前后顺序不变,所以插入排序是稳定的排序算法。
- 插入排序的最好时间复杂度是O(n),最坏时间复杂度为O(n平方)。
为什么插入排序比冒泡排序更受欢迎?
从如上代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个。
这里我在本地也做了个简单的测试,随机生成不规则的100000条数据,然后分别使用冒泡排序和插入排序进行测试。
测试程序代码如下:
/**
* 随机生成len条数据,最大值为max
* @param len
* @param max
* @return
*/
public static int[] gennerateArray(int len, int max) {
int[] arr = new int[len];
for (int i = 0; i < arr.length; i++) {
arr[i] = (int) (Math.random() * max);
}
return arr;
}
//性能测试程序,
public static void main(String[] args) {
int[] arr = gennerateArray(100000, 10000000);
long start = System.currentTimeMillis();
bubble(arr, arr.length);
long end = System.currentTimeMillis();
System.out.println("冒泡排序耗时------> " + (end - start) + "ms");
long insertStart = System.currentTimeMillis();
insertionSort(arr,arr.length);
long insertEnd = System.currentTimeMillis();
System.out.println("插入排序耗时------> " + (insertEnd - insertStart) + "ms");
}
- 冒泡排序最终耗时大概为
24157ms - 插入排序最终耗时大概为
2228ms
性能差异,一目了然。
这就是为什么插入排序为什么比冒泡排序受欢迎的原因。




