


Hive导入数据的4中常用方式:
- 从本地文件系统中导入数据到Hive表;
- 从hdfs上导入数据到Hive表;
- 从别的表中查询出相应的数据并导入到Hive表中;
- 在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中。
从本地文件系统中导入数据到Hive表
先在Hive里面创建好表。
CREATE TABLE hive.student ( id VARCHAR(255) primary key DISABLE NOVALIDATE RELY comment '主键', name VARCHAR(255) comment '姓名', xb INT NOT NULL comment '性别', age INT comment '年龄' ) row format delimited fields terminated by ',' comment '学生表';
创建本地文件/home/add.txt,txt格式的就可以,上述创建表的制表符为",",数据需要用","分割,如下:
1,zhangsan,男,12
2,lisi,男,11
3,wangwu,女,10
创建完毕后,使用hive命令将当前add.txt文件导入hive数据源中
hive>load data local inpath '/home/add.txt' into table student;
导入成功后,就可以在hdfs目录中看到对应的数据了。如下图
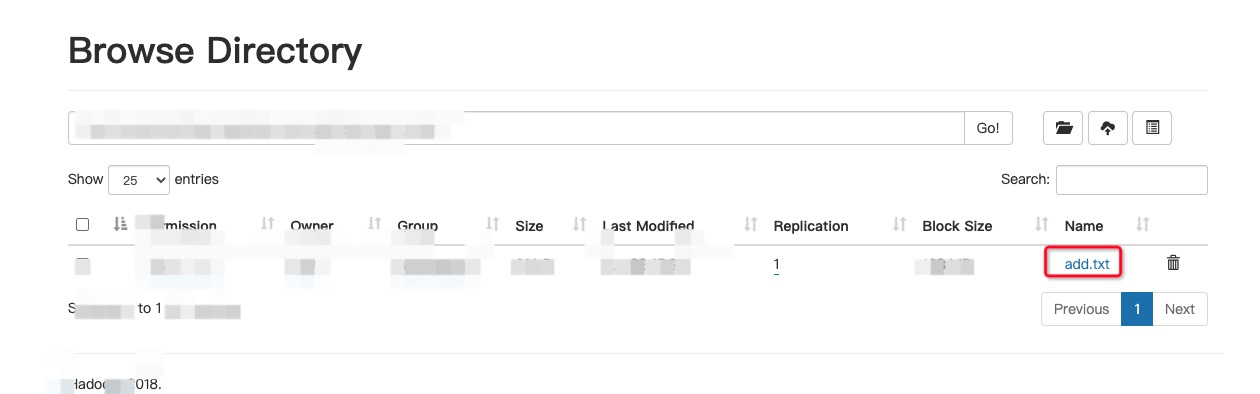
和我们熟悉的关系型数据库不一样,Hive现在还不支持在INSERT语句里面直接给出一组记录的文字形式,也就是说,Hive并不支持INSERT INTO …. VALUES形式的语句。
HDFS上导入数据到Hive表
从本地文件系统中将数据导入到Hive表的过程中,其实是先将数据临时复制到HDFS的一个目录下(典型的情况是复制到上传用户的HDFS home目录下,比如/home/hdfs/),然后再将数据从那个临时目录下移动(注意,这里说的是移动,不是复制!)到对应的Hive表的数据目录里面。既然如此,那么Hive肯定支持将数据直接从HDFS上的一个目录移动到相应Hive表的数据目录下,假设有下面这个文件/home/hdfs/add.txt,具体的操作如下:
hadoop fs -cat /home/hdfs/add.txt 1,zhangsan,男,12 2,lisi,男,11 3,wangwu,女,10
上面是需要插入数据的内容,这个文件是存放在HDFS上/home/hdfs目录(和一中提到的不同,一中提到的文件是存放在本地文件系统上)里面,我们可以通过下面的命令将这个文件里面的内容导入到Hive表中,具体操作如下:
hive> load data inpath '/home/hdfs/add.txt' into table student;
进行查询数据
hive> select * from wyp; 1 zhangsan 男 12 2 lisi 男 11 3 wangwu 女 10
从上面的执行结果我们可以看到,数据的确导入到student表中了!请注意load data inpath ‘/home/hdfs/add.txt’ into table student,里面是没有local这个单词的,这个是和一中的区别。
从别的表中查询出相应的数据并导入到Hive表中
假设Hive中有test表,其建表语句如下所示:
CREATE TABLE hive.test ( id VARCHAR(255) primary key DISABLE NOVALIDATE RELY comment '主键', name VARCHAR(255) comment '姓名', xb INT NOT NULL comment '性别', age INT comment '年龄' ) partitioned by age(int) row format delimited fields terminated by ',' comment '学生表';
大体和wyp表的建表语句类似,只不过test表里面用age作为了分区字段。对于分区,这里在做解释一下:
分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如student表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse/dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
下面语句就是将student表中的查询结果并插入到test表中:
hive> insert into table test
> partition (age='25')
> select id, name, age
> from student;
如果目标表(test)中不存在分区字段,可以去掉partition(age=’25′)语句。
在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中
在实际情况中,表的输出结果可能太多,不适于显示在控制台上,这时候,将Hive的查询输出结果直接存在一个新的表中是非常方便的,我们称这种情况为CTAS(create table .. as select)如下:
hive> create table test1
> as
> select id, name, age
> from student;
数据就插入到test1表中去了,CTAS操作是原子的,因此如果select查询由于某种原因而失败,新表是不会创建的。


