ORC File文件结构
ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。和Parquet类似,它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Spark SQL、Presto等查询引擎支持,但是Impala对于ORC目前没有支持,仍然使用Parquet作为主要的列式存储格式。2015年ORC项目被Apache项目基金会提升为Apache顶级项目。ORC具有以下一些优势:
1、ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比。
2、文件是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅节省HDFS存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了。
3、提供了多种索引,row group index、bloom filter index。
4、ORC可以支持复杂的数据结构(比如Map等)
ORC File存储格式
ORC的全称是(Optimized Record Columnar),优化后的列式记录,ORC在RCFile的基础上进行了一定的改进,所以与RCFile相比,具有以下一些优势:
1、ORC中的特定的序列化与反序列化操作可以使ORC file writer根据数据类型进行写出。
2、提供了多种RCFile中没有的indexes,这些indexes可以使ORC的reader很快的读到需要的数据,并且跳过无用数据,这使得ORC文件中的数据可以很快的得到访问。
3、由于ORC file writer可以根据数据类型进行写出,所以ORC可以支持复杂的数据结构(比如Map, Struct等)。
4、ORC的stripe默认大小更大,为ORC writer提供了一个memory manager来管理内存使用情况。
ORC File存储方法
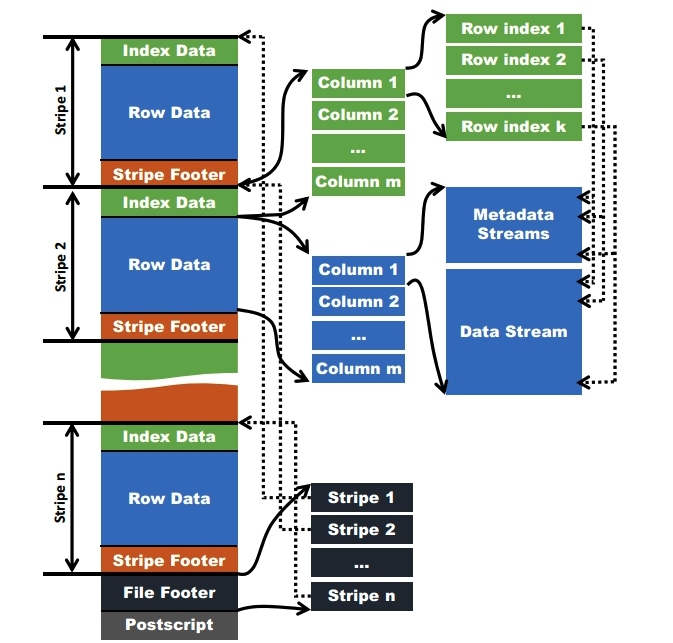
在ORC格式的hive表中,数据首先会被按照行切分成多个stripes,之后在每个stripe内数据按列为单位进行存储,所有列的内容都保存在同一个文件中。每个stripe的大小默认为256MB, 与RCFile的4MB的stripe相比, ORC格式的文件读取更加高效。
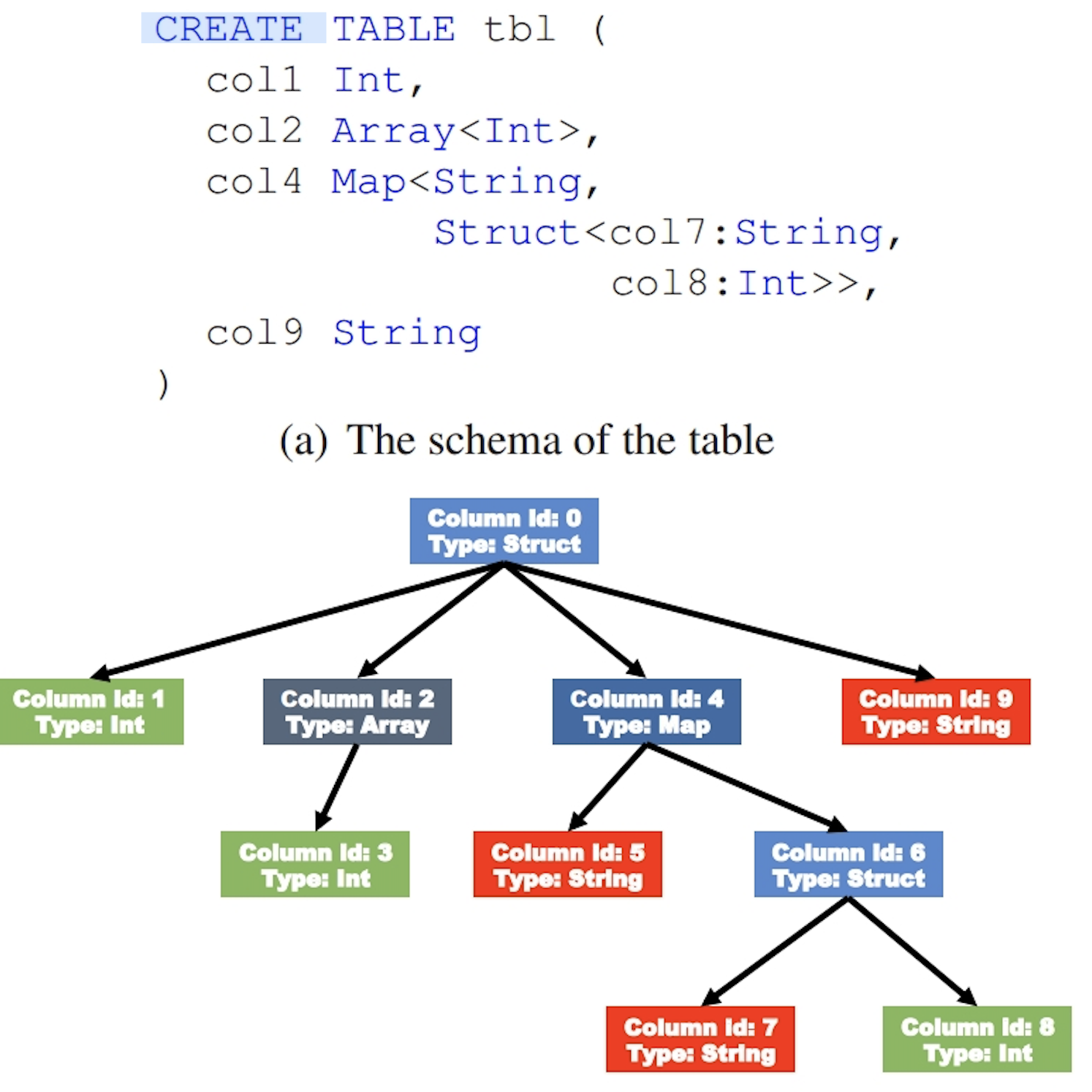
对于复杂的数据类型,比如Map,ORC文件会将一个复杂数据类型字段解析成多个子字段。
当字段类型都被解析后,会由这些字段类型组成一个字段树,只有树的叶子节点才会保存表数据,这些叶子节点中的数据形成一个数据流,如上图中的Data Stream。
为了使ORC文件的reader更加高效的读取数据,字段的metadata会保存在Meta Stream中。在字段树中,每一个非叶子节点记录的就是字段的metadata,比如对一个array来说,会记录它的长度。下图根据表的字段类型生成了一个对应的字段树。